Alexa, Please Send This To My Screen
Thoughts on designing seamless voice experiences


“Alexa, what’s new?”
I walk out of the bedroom and listen to the news while preparing breakfast.
I’ve gotten very used to Alexa. It’s not that it has dramatically changed how I consume content, but it’s a great way to get things done hands-free while focusing on other stuff in the living room or the–
Wait.
My mind’s wandering again.
What was Alexa just saying? Who was that guy again, the one who was just mentioned? I recognize his name, but I can’t remember what he looks like.
Let’s find out.
I’m reaching for my phone, which is on the table next to my couch.
TL;DR: We need to think in ecosystems and build voice interfaces into continuous and complementary experiences to finally make them useful.
Here’s why:
Voice as an Interface
There are now more than 10,000 skills for Amazon Alexa (= apps for the virtual assistant living inside of Amazon Echo). However, we’re just beginning to grasp what place voice will take in our everyday lives. Currently, it’s not the best experience. Most voice skills have enormous problems with retention.
Voice skills will probably go through the same hype as chatbots did: most will feel like search experiences that could also be done on a website. I don’t see this as a problem, it’s typical when a new interface emerges.
As John Borthwick mentioned, the first 6 months after the introduction of the App Store, new iOS apps rather resembled iterations of web pages. It took time to develop native experiences. And it will be the same with voice interfaces.
What is a Voice Interface?
With the increasing amounts of Amazon Echo devices in households, now everyone seems to be talking about voice interfaces. But what are we exactly talking about?
“I define a Voice Computing product as any bot-like service which has no GUI (Graphic User Interface) at all — its only input or output from a user’s perspective is through his or her voice and ears.” — Matt Hartman
One of the most important differences I see in voice interfaces is how distinctively we can separate usage between the two forms of interaction: input and output.
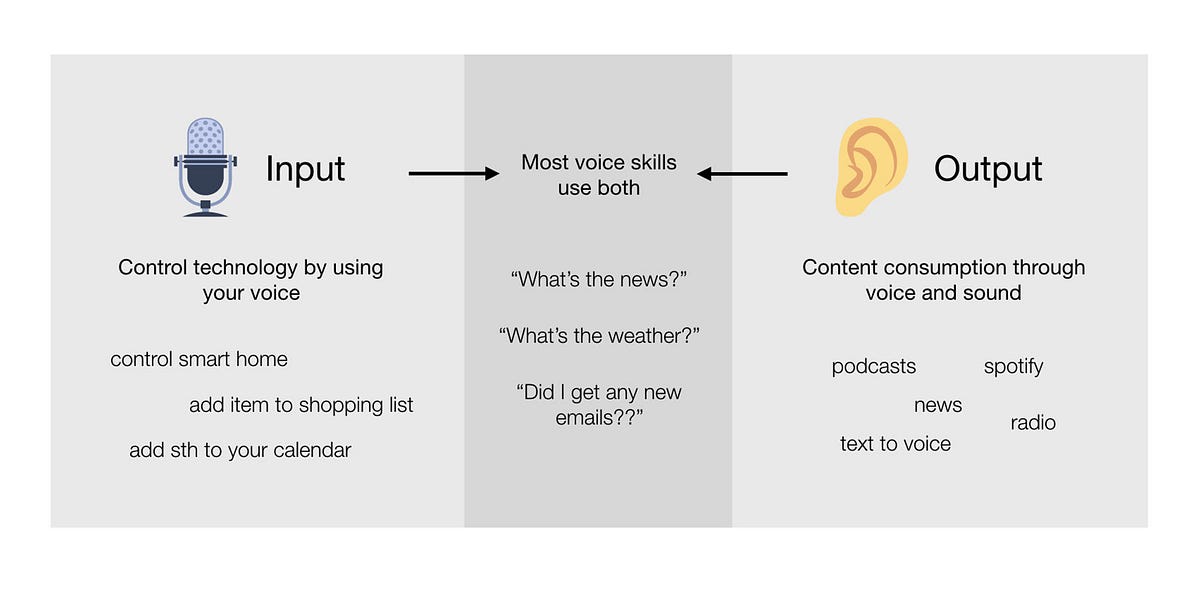
🎤 Voice as Input is about controlling software just by saying something.
Whatever I’m doing, preparing food, cleaning the kitchen, I can still access a computer without having to reach my phone, the remote, or go to my laptop. Even when I’m on my laptop, I can still ask for stuff without having to stop what I’m currently doing.
Today, you can already control your lights or change TV channels with Alexa.
👂 Voice as Output is about consuming information just by listening.
While this isn’t something completely new (we’ve been running around wearing headphones for years), it’s still worth mentioning. I can listen to the news or weather forecasts while doing something else.
Voice as output is especially interesting as it opens up the possibility to be connected to information at times we cannot look at a screen.
When brainstorming new skills for Alexa, Alexander and I are constantly trying to separate input from output to understand how we could add the most value to current solutions.
But currently, that’s very difficult to do with Alexa skills.
Alexa: Input -> Output
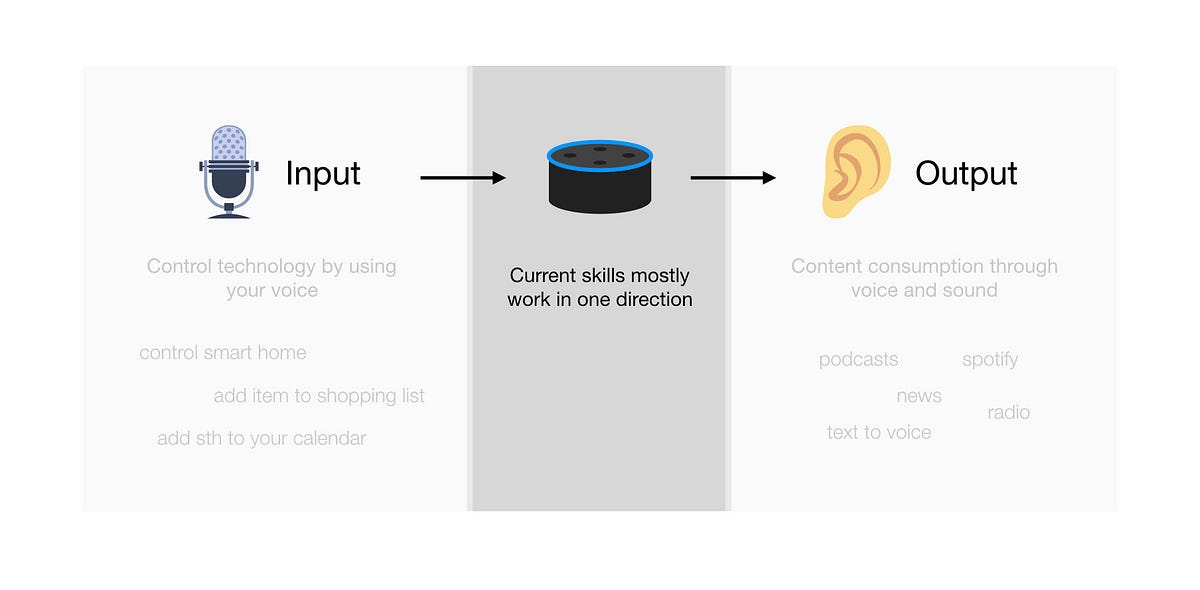
Currently, Alexa mostly offers input and output bundled together. We say something and get information right away.
These two forms of interaction can work extremely well together in several contexts (in the kitchen, on the couch), but they can also be completely separated. I wouldn’t talk to my phone on the bus, but would definitely love to listen to things. And in other cases, I might want to tell my apps to do something, but consume the content later.
And I believe this is especially interesting when we take into account that contexts can change while we’re interacting with technology.
Shifting Contexts
We’re always talking about the interaction with voice while doing something else like cooking or watching TV. However, what I found my Echo most useful for is when I’m preparing to leave the house: I’m asking a Berlin-based transportation skill which route to take.
The first part of the information (which subway to take, how long it takes, when to leave) is perfect at home. But I need to consume additional information (where to transfer, where to walk afterwards) in a different context: while on the go.
Currently, an interaction like this is not possible, as most skills lack the functionality to move content across devices.
Current Skills are Silos
For skill developers (without a lot of development effort, without an existing user base in their own native apps), it’s currently almost impossible to build something other than immediate input/output apps.
There’s some functionality available by Amazon with their Home Cards and even the possibility to display content on a Fire Tablet. But that’s it.
In our opinion, however, it’s critical to think about experiences that connect different devices that work best for each context.
Multi-Device Experiences
“Greater benefit would come from people getting the right thing, at the right time, on the best (available) device”–Michal Levin
With the beginning of mobile technology and fragmented devices and screen sizes, people started thinking about ways to provide the best experience across platforms.
I read the book “Designing Multi-Device Experiences” by Michal Levin about 2 years ago and was fascinated by her thinking about using context to design product experiences across devices. And I find it especially useful now, as we need to add voice to the mix as well.
In her 3Cs framework, Levin describes how products can be designed to serve the needs across devices:
- Consistent
- Continuous
- Complementary
Consistent: Keep the same experience across devices
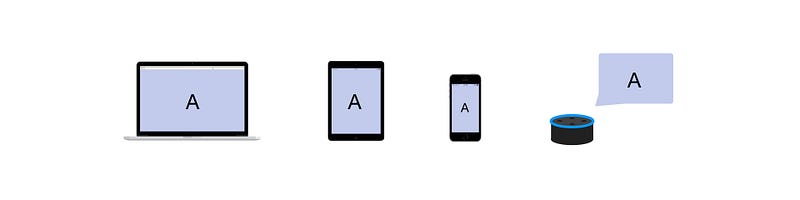
This approach displays content in the same way across the ecosystem (with some adjustments, e.g. smaller fonts). Responsive design can still be seen as some form of consistent design, as it’s still displaying the same content across devices.
The problem with current bots and voice skills is, that they mostly use a consistent approach, as they replicate search experiences from the web and mobile apps. And for some contexts, that’s great! For others, not so much.
But there’s two more approaches that are interesting to look into:
Continuous: The experience is passed from one device to the other
Great continuous experiences can be ones where you do the research on your desktop at home, and then access the content while on the go (e.g. shopping list in a cooking app, Google Maps directions).
I have always been a great fan of tools like Pushbullet for pushing content across devices. Or this functionality in Google Maps:
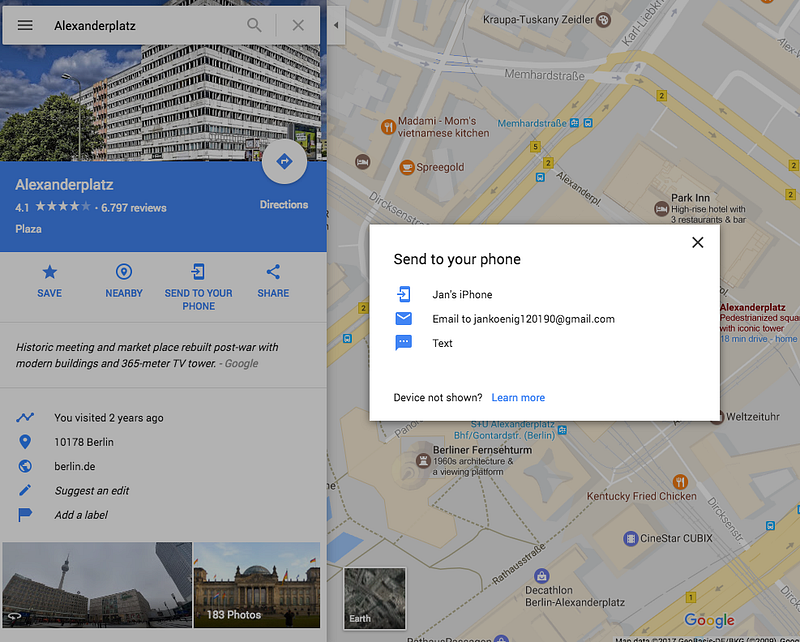
Continuous design is perfect for use cases that could undergo shifting contexts like a change of location.
Complementary: Devices work as connected group and complement each other in a new experience.
This can be either done with collaboration (devices work with each other) or control (one device is used as some sort of remote).
An example of complementary design could be a smart home hub that controls your lights from your tablet, or an iPad multiplayer game that uses iPhones as controllers.

And here is where it gets interesting: Some smart home skills for Alexa are already complementary experiences.
To have a more seamless experience across devices, I wish there would be more skills that use continuous and complementary design.
Voice in a Multi-Device World
Voice will never be the only interface we use. But it will be one with significantly growing usage.
We believe that voice should be intertwined in current technology and allow exchanging information across devices. Software should allow us to shift contexts, as we interact with it. It should offer the right interface at the right moment.
Or, as M.G. Siegler put it, it should be “computing in concert.”
Example: Mosaic
One of the only examples that show signs of multi-device experiences that incorporate voice is Mosaic.
The startup offers chatbots and voice skills that help you talk to your home. When I got the most important news (in a morning workflow, which is a feature Mosaic offers), Alexa asked me if I want to have the article sent. I said “send article” and immediately got a message by the Mosaic chatbot with a link.
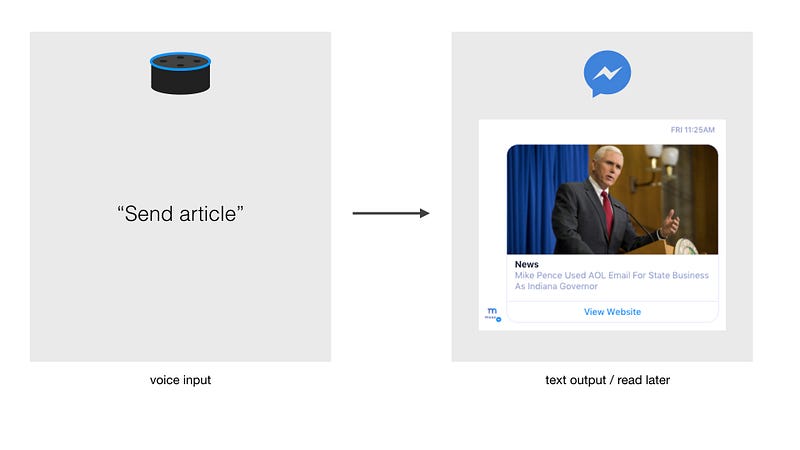
For me, this is a great, seamless experience. At a later point, I would love to immediately add articles like this to my Instapaper.
Ecosystem Thinking
“Deliver a product ecosystem that serves the end-to-end user journey across devices” — Michal Levin
Experiences like this require product designers to think in ecosystems: What are the contexts my users could be in, and how could I deliver information in the best way across devices?
I believe this will become more important as we’re increasingly moving between devices and interface modalities, as Chris Messina put it:
Current Challenges
Currently, Amazon’s Account Linking only allows linking a skill to one account. This makes it extremely difficult for voice-first startups that don’t have existing user bases with native apps on their smartphones.
To allow cross-device pushing, developers would need to set up their own oAuth system, develop an app, make the user download the app, and link the skill-user to the app-user. And this is quite a hassle to do for one skill.
We figure Amazon (and other voice platforms) are currently working on a solution, but don’t know exactly how it could look like. And hopefully, this won’t result in walled gardens.
Conclusion
The challenge with current voice experiences is to build something that seamlessly fits into current product ecosystems.
To do this, we need to think about creating continuous and complementary interfaces based on the context the user is in. And we also need to keep in mind that context can change while a user interacts with software.
Building voice into cross-device experiences is difficult to do, but necessary to take it to the next level.
A few more points to think about
Here’s some more thoughts that fall into this category, but didn’t really fit in the text above.
The Interaction Effect
In the moment I’m writing this, I’m still thinking in old experiences, based on what I learned from websites, native apps, and chatbots. It’s difficult to imagine how the mainstream usage of voice could change how people use their smartphones or computers. This is why I believe it’s important to come back to these thoughts in a few months (and years) to see if anything changed.
Michal Levin calls this the Interaction Effect: “The usage patterns of one device change depending on the availability of another device.”
Notifications
Push notifications are the thinnest available layer that allow apps to make content accessible across devices. And the prevalence of messaging apps makes notification even better. Why? You can plug into an existing platform (like Mosaic did with Facebook Messenger) and let the user decide where to consume the content.
Some people noticed a shift from push to pull in the last years, where we’re moving from people actively seeking information to software knowing when to push the right information.
However, I’m wondering how the current developments of voice interfaces fit into that category, as they mostly allow us to pull information, rather than push.
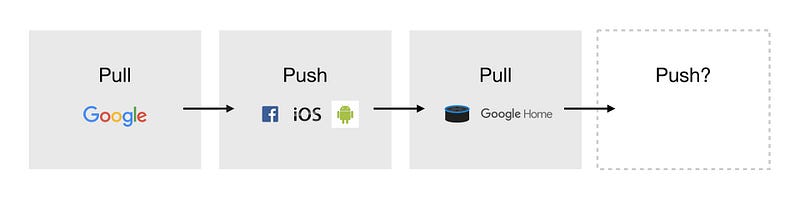
It will probably always be an interaction of both push and pull. However, I find it interesting to think about when software should appear and when not:
Be like Batman
I believe the rise of voice will make adaptive user interfaces even more important. No matter if you call it ubiquitous computing or on-demand interfaces, it will be necessary for software to only appear when it’s needed.
Like Batman.
I once wrote an article about onboarding and used this quote:
“The signal goes on and he shows up. That’s the way it’s been, that’s the way it will be.” ― James Gordon
Today, I feel it has become even more important. Check it out here.
If you want to read more about adaptive systems, I highly recommend this article by Avi Itzkovitch (old, but gold).