Dialogue Management: A Comprehensive Introduction (2021 Edition)
Understanding approaches to conversational voice and chat systems

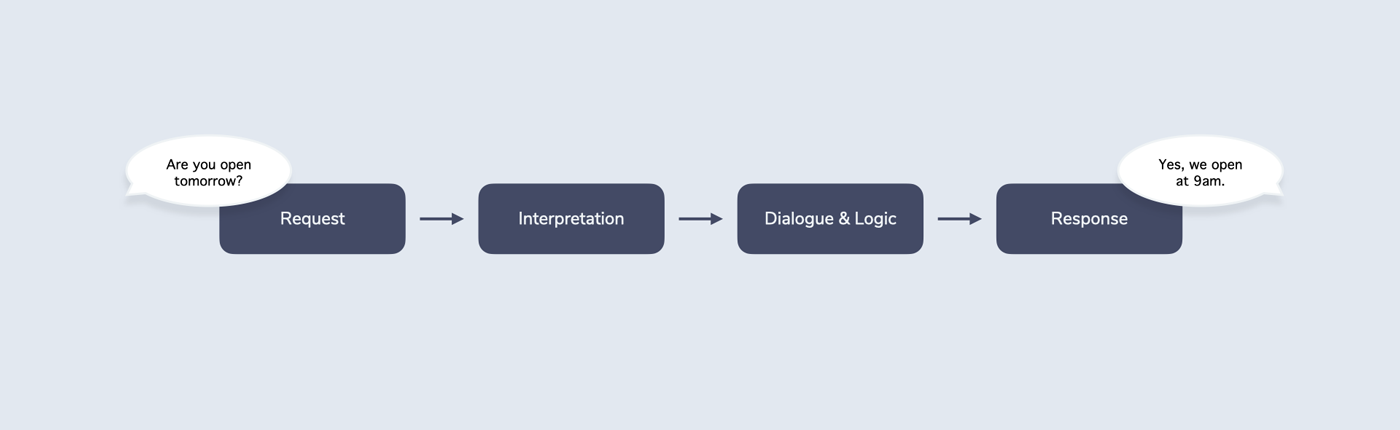
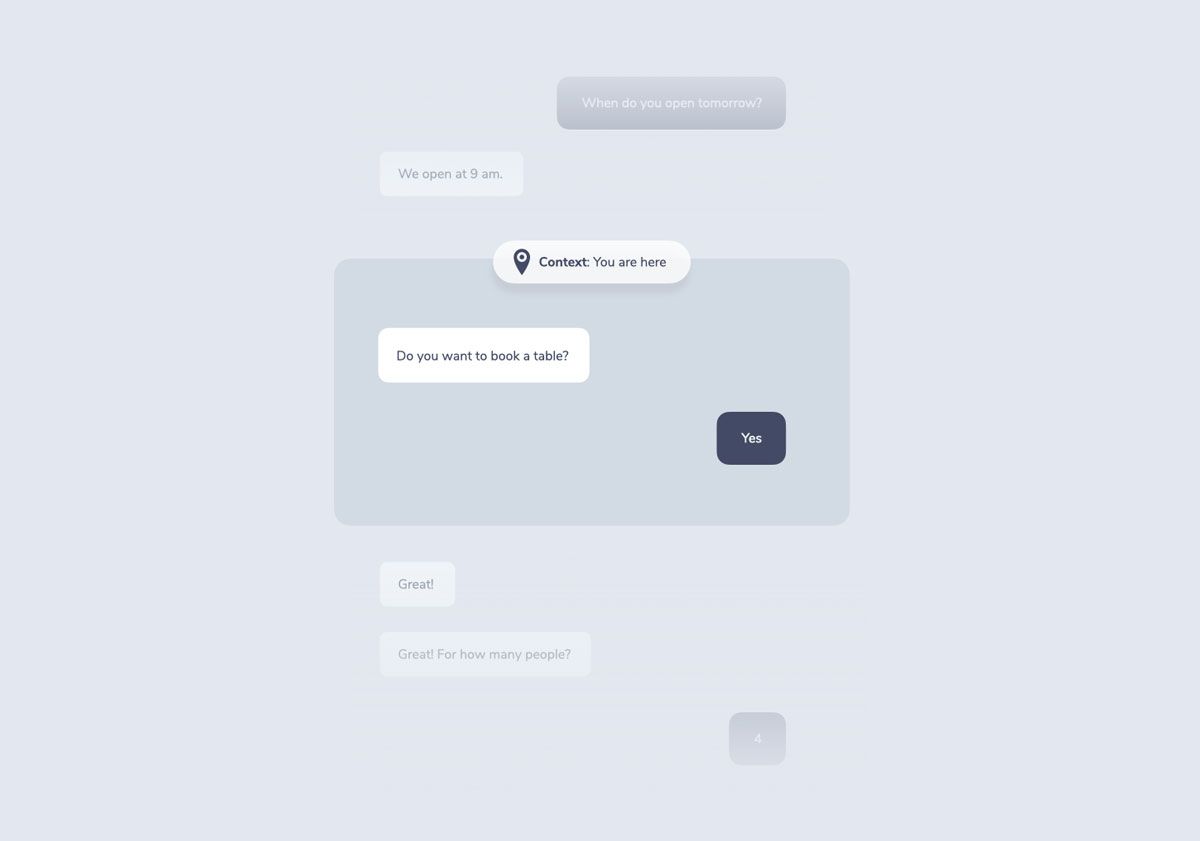
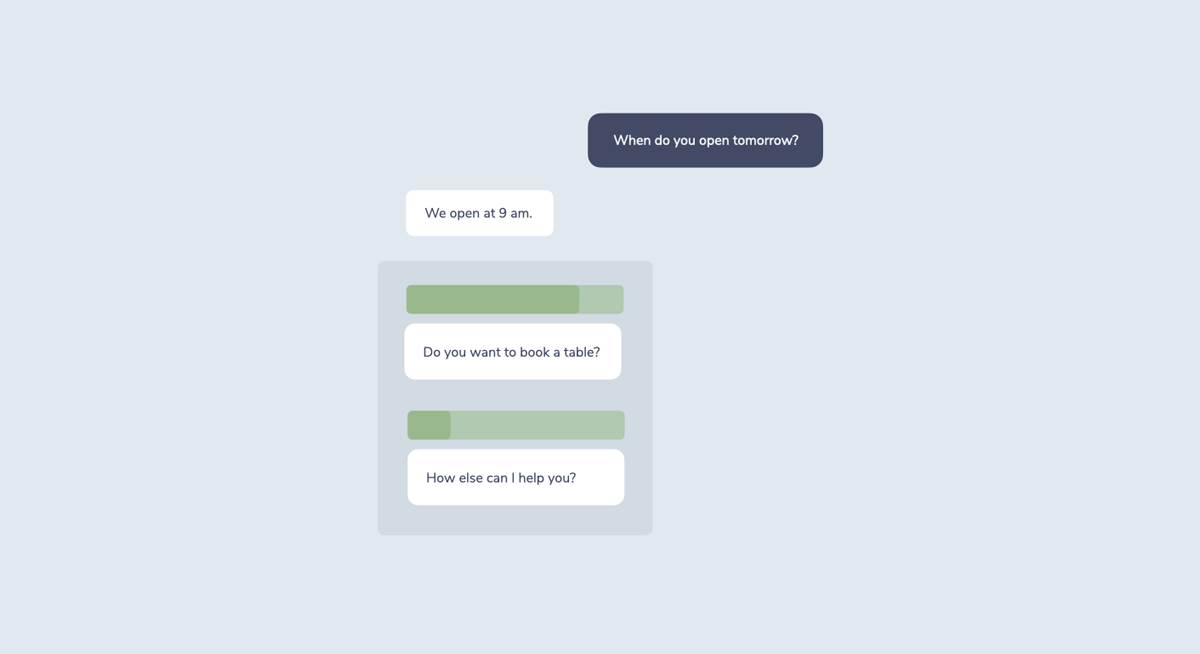
“When do you open tomorrow?”
“We open at 9 am. Do you want to book a table?”
How does a conversational system decide how it should respond to a user’s request? In which cases should it ask for clarification, deliver facts, or present a follow-up question?
In this post, I want to introduce the topic of dialogue management as one of the critical ingredients of conversational systems (like voice apps and chatbots). This 3,000+ words in-depth introduction provides answers to the following questions:
- What is dialogue management?
- What are popular approaches like finite state machines, form-based systems, and probabilistic dialogue management? What are pros and cons of each?
- Is there an ideal approach?
Multi-Turn Conversations and RIDR
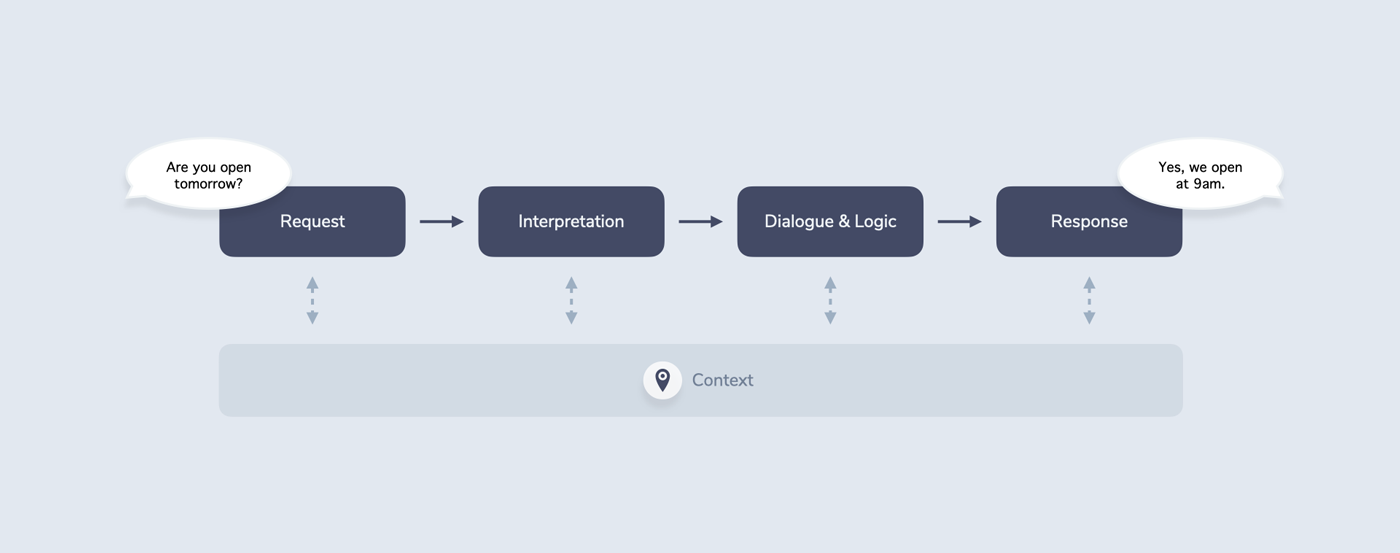
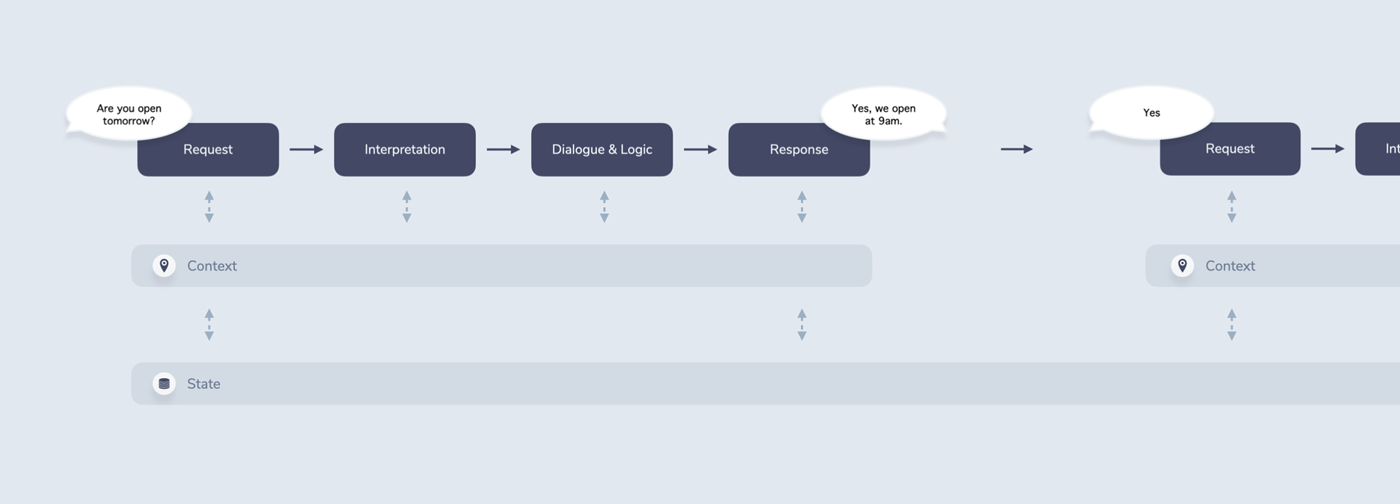
In An Introduction to Voice and Multimodal Interactions, I introduce the RIDR (Request - Interpretation - Dialogue & Logic - Response) Lifecycle as a framework for the various steps involved in getting from a user request (e.g. a spoken “Are you open tomorrow?”) to a system response (e.g. a spoken “Yes, we open at 9 am”).
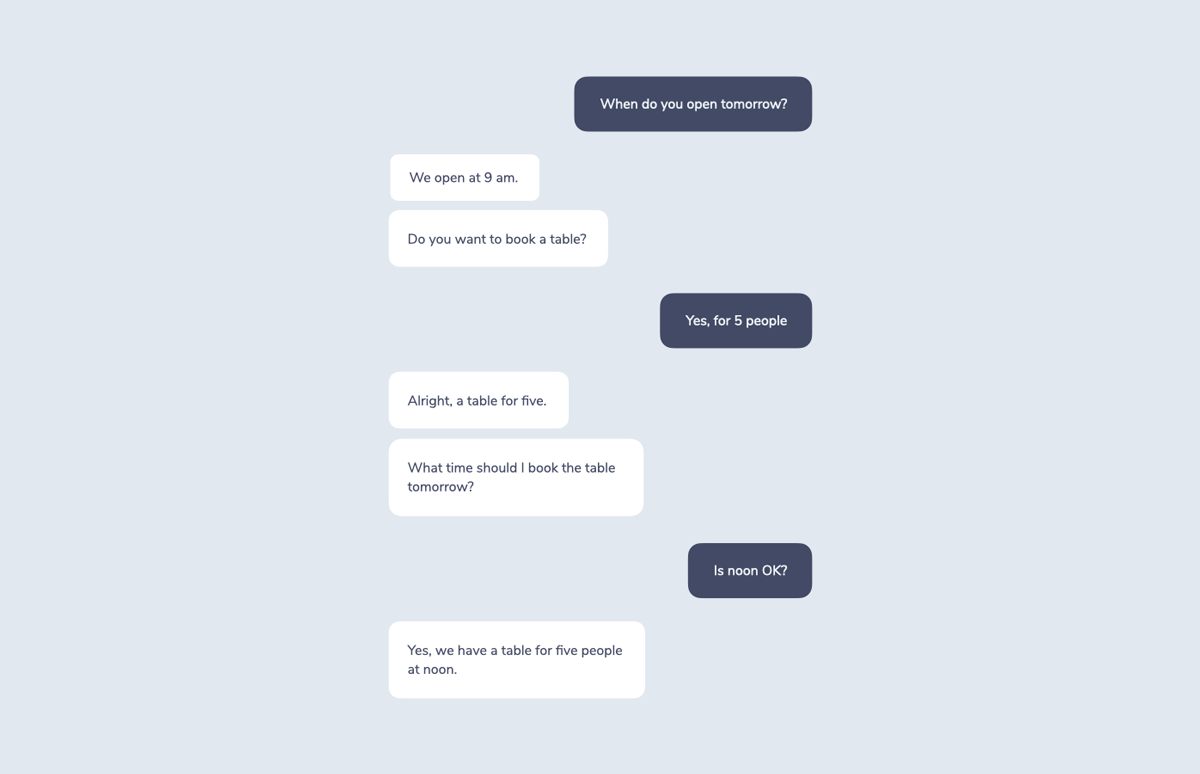
This seems to be a straightforward interaction. To make it a little more interesting, let’s add a follow-up question to the response: “Do you want to book a table?”
A user answering this question would kick off another flow through the RIDR Lifecycle:
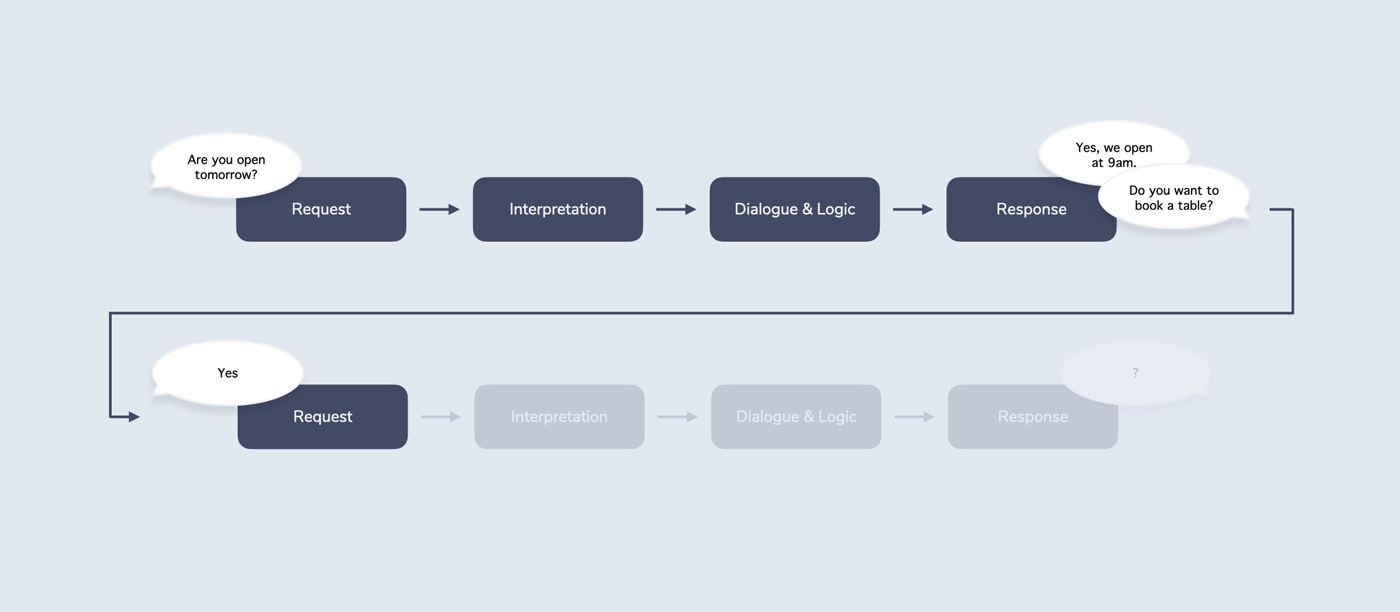
These kinds of strung together interactions are called multi-turn conversations. In that terminology, a turn is either the user or the system saying something. Multi-turn suggests that there is some back and forth between both parties.
For conversations like this, it becomes necessary that the system builds up some sort of memory. “Yes” can mean completely different things depending on what happened during the last turn.

This is where the third step of RIDR comes into play: Dialogue & Logic.
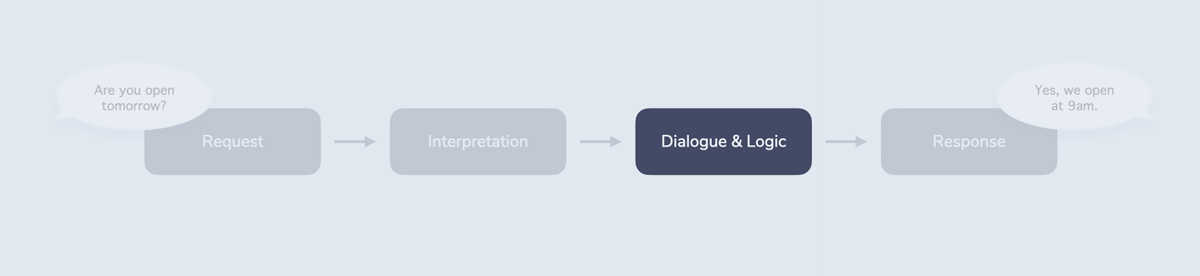
In general, Dialogue & Logic takes structured input (e.g. an intent) from the Interpretation step and determines some structured output. This output is then passed to the Response step where it is returned to the user.
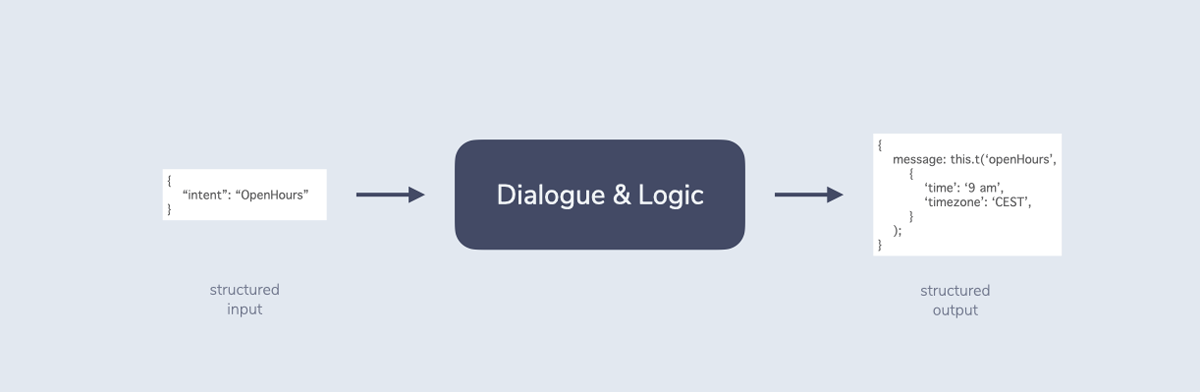
As we’ve learned above, though, an intent (e.g. “Yes”) is not enough. We need to find ways for the system to remember the last turn (and potentially more) and take into account other contextual factors to make decisions about next steps.
This is what Dialogue Management, a key element of Dialogue & Logic, is responsible for.
What is Dialogue Management?
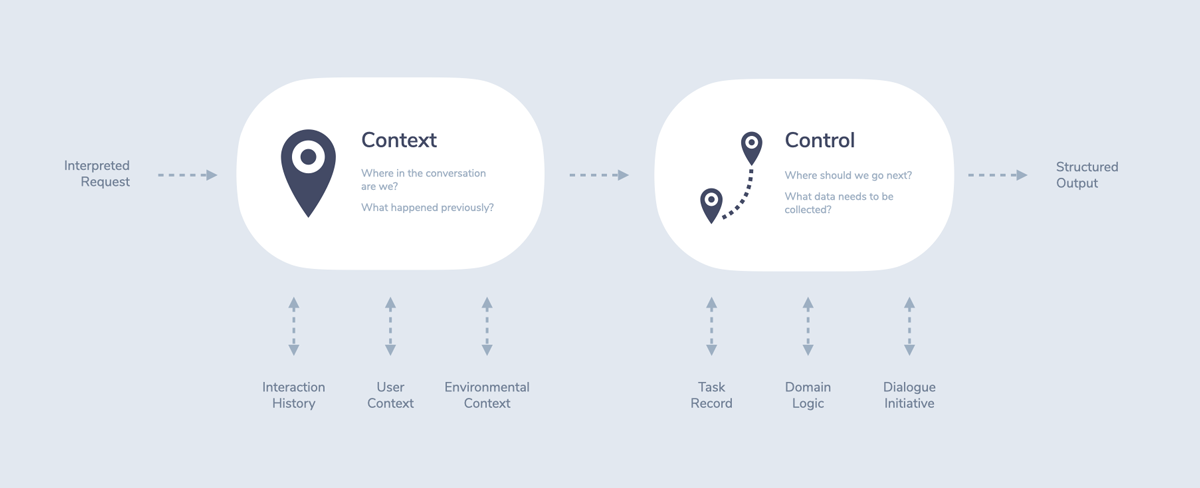
Dialogue management (or dialog management) is responsible for handling the conversational logic of a voice or chat system. It usually consists of two main areas of focus:
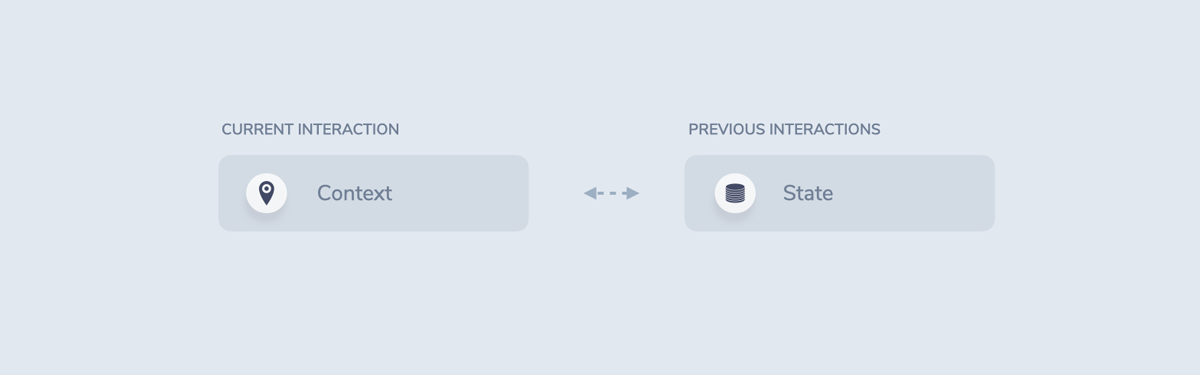
- Context: All data that helps us understand where in the conversation we currently are
- Control: Deciding where the conversation should go next
Dialogue Context
Context is the “you are here” pin for a conversational system. Tracking and managing it is essential: If we don’t know where we are, we don’t know where to go next.
Context includes all types of data a system uses to relate the current interaction to the bigger picture of the conversation. Examples could be:
- Interaction History: What happened before? Was the user’s request the answer to a previous question? This is not only important for the “Yes” example from above, but also for making sense of linguistic elements like anaphora, ellipsis, and deixis.
- Request Context: What do we know about this interaction? What device is used, what types of modalities are supported?
- User Context: What do we know about the user? Do they have certain preferences?
- Environmental Context: What else is important for this conversation? Is it day or night? Weekend? This could also include sensory data from IoT devices.
These types of data could come from different elements of the conversational system. All steps of the RIDR lifecycle could potentially read from and write into the context. This approach to data management is also called information state update (ISU) theory in research.
A note on the term context: In research, this is also referred to as dialogue state, which sometimes causes confusion with the term state machine (more on that approach below). Context and state are defined differently across disciplines, so let’s dive a bit deeper and find a useful definition for this and upcoming articles.
To me, there is a slight difference between context and state. While context is all the data the system uses to evaluate the current interaction, state is all the data the system remembers from previous interactions.
As a rule of thumb, state can be seen as historic context. The system decides which context elements should be remembered for later use and stores them in a database or other type of memory. In the next interaction, it then retrieves the state to take into account in the current context.
In a later section, we’re going to dive into a few approaches to managing context and state.
Dialogue Control
Dialogue Control is responsible for navigating the next steps of a conversation.
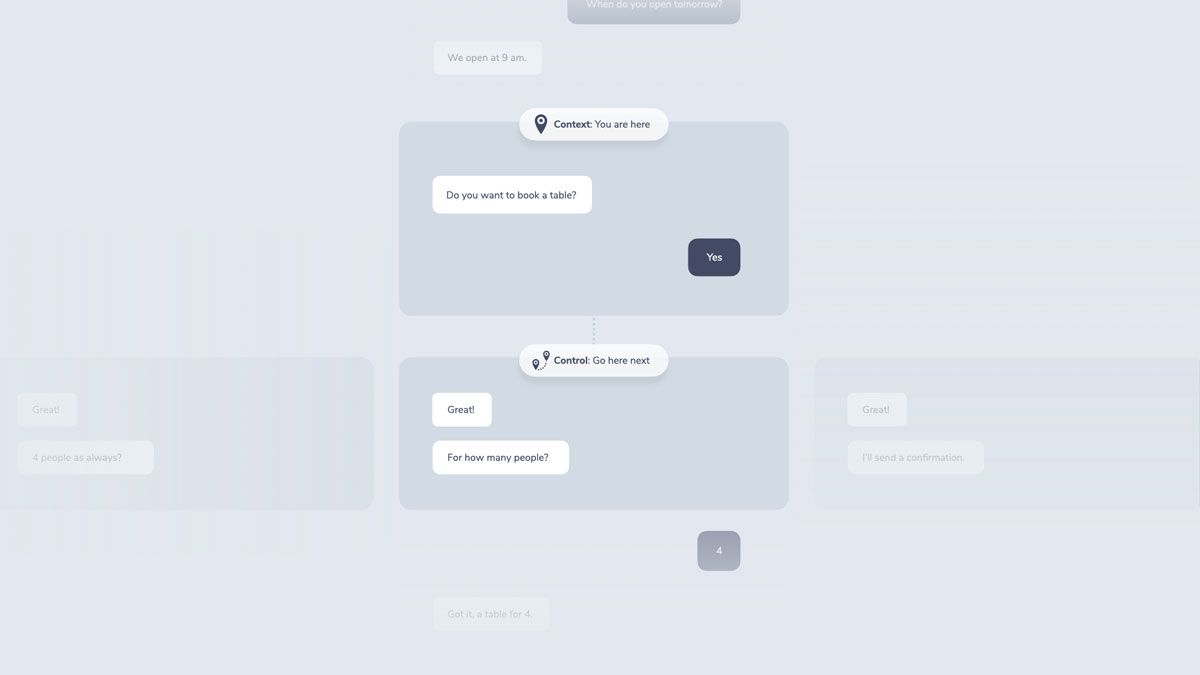
Control responds to the following questions:
- Task Record: Is there any additional information that is missing and needs to be collected from the user?
- Domain Logic: Is there any data that we need that is relevant for the interaction? Do we need to make any API calls to internal or external services?
- Initiative: Who is leading the flow of the conversation? Does the system just respond to user requests (user initiative) or does the system guide the user through a series of steps (system initiative)? Mixed-initiative controls are also possible.
There are many different ways control could be implemented (this task is also called dialogue flow sometimes). While many systems use a rules-based approach where custom logic determines next steps, there are also a number of emerging probabilistic methods.
In the next section, we’re going to examine three approaches to dialogue management that look into the differences in how context and control could be implemented.
Approaches to Dialogue Management
If you talk to researchers and practitioners in the field of conversational AI, you quickly realize that the challenge of dialogue management is far from being solved. There are still a lot of missing pieces holding us back from building a robust solution that understands unanticipated input, interprets and remembers all sorts of contextual information, and then intelligently makes decisions about next steps in a natural way.
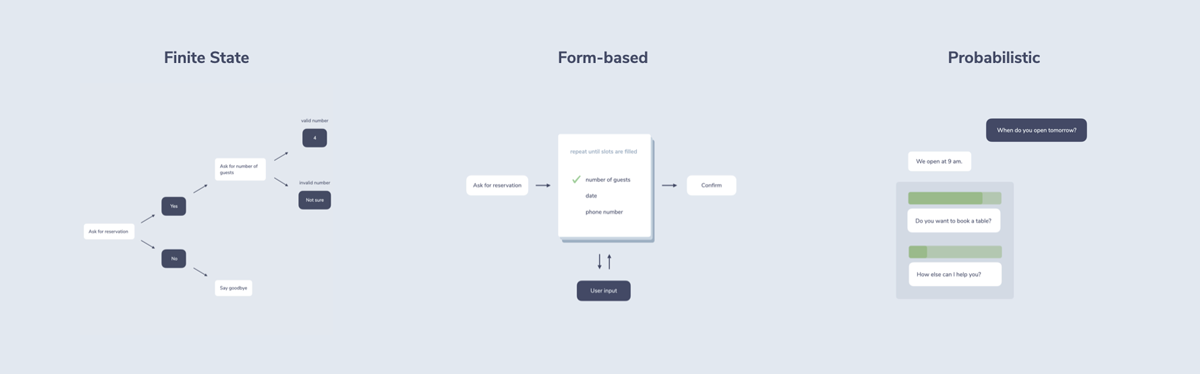
To get closer to this, many approaches to dialogue management have been created and tested over the years. Three popular ones are:
- Finite State: A model that uses a state machine to keep track of the conversation. If your conversational system is designed with tools like flowcharts, it’s probably using the finite state approach.
- Form-based: A model with the goal of reducing the number of potential paths that have to be explicitly designed. Especially useful for slot filling, the process of collecting data from the customer.
- Probabilistic: A model that uses training data to decide the next steps of the conversation.
Let’s take a closer look at each of these approaches.
Finite State Dialogue Management
Finite state uses the concept of a state machine to track and manage the dialogue. Although technically a bit different (you can find a comparison here), so-called flowcharts are often used as a visual abstraction for state machine based conversation design.
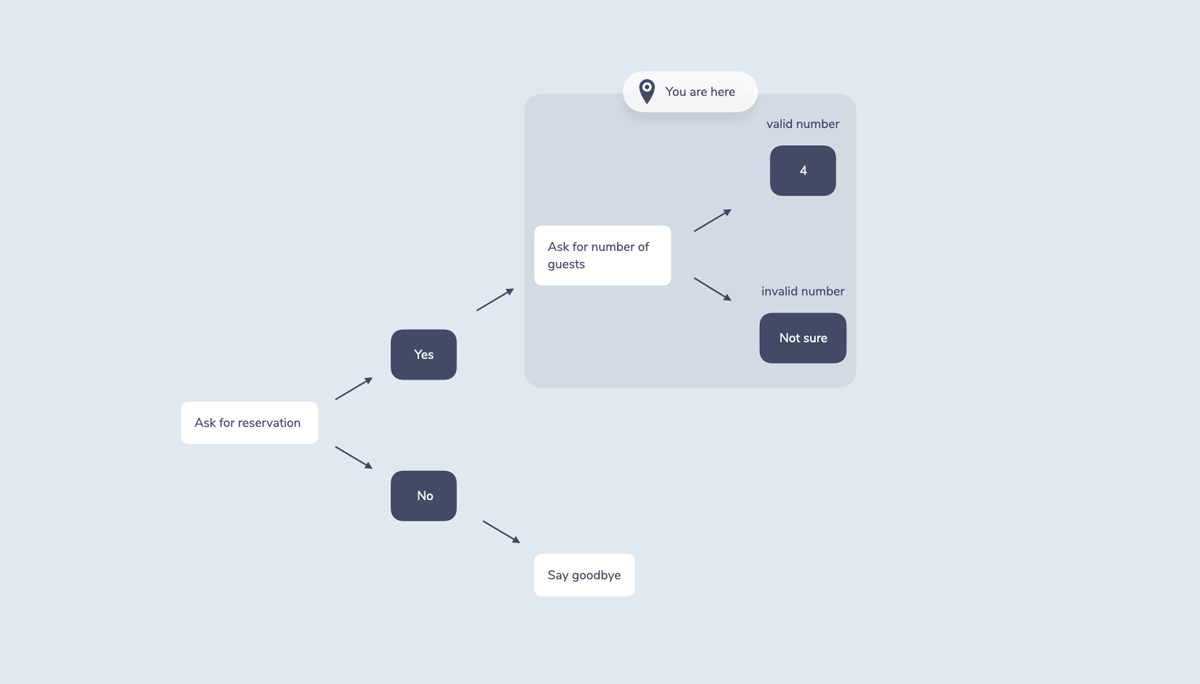
Here’s a simplified version of a flowchart of a system (white boxes) asking a user (blue boxes) if they want to make a reservation:
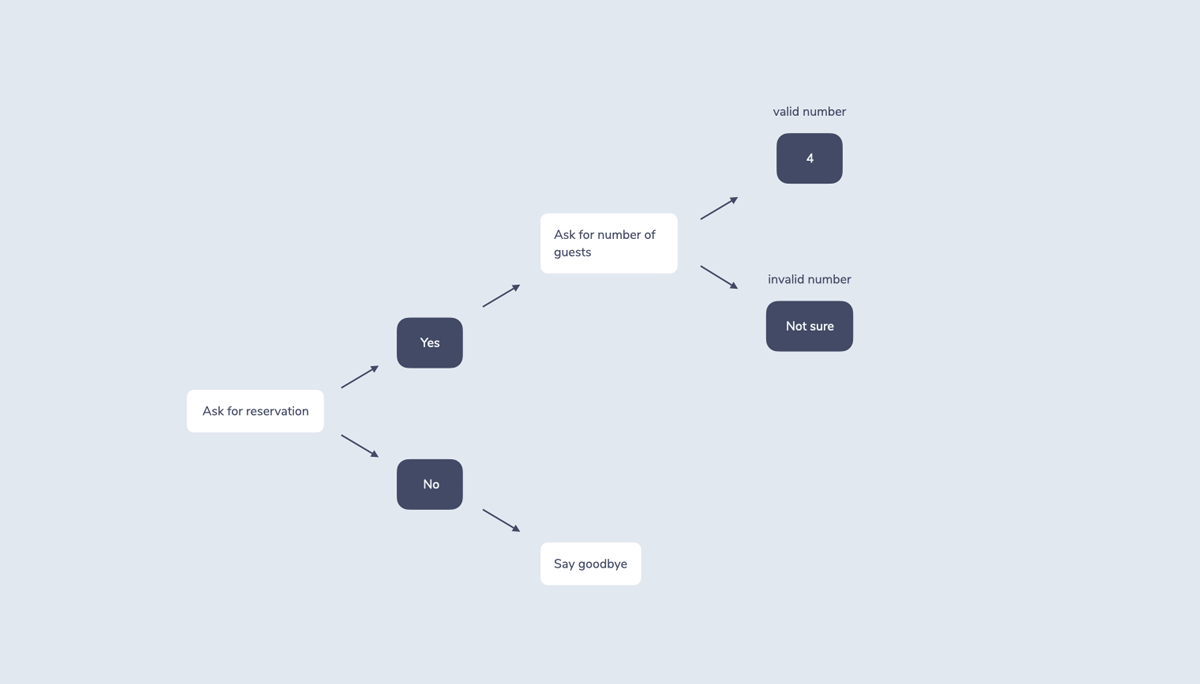
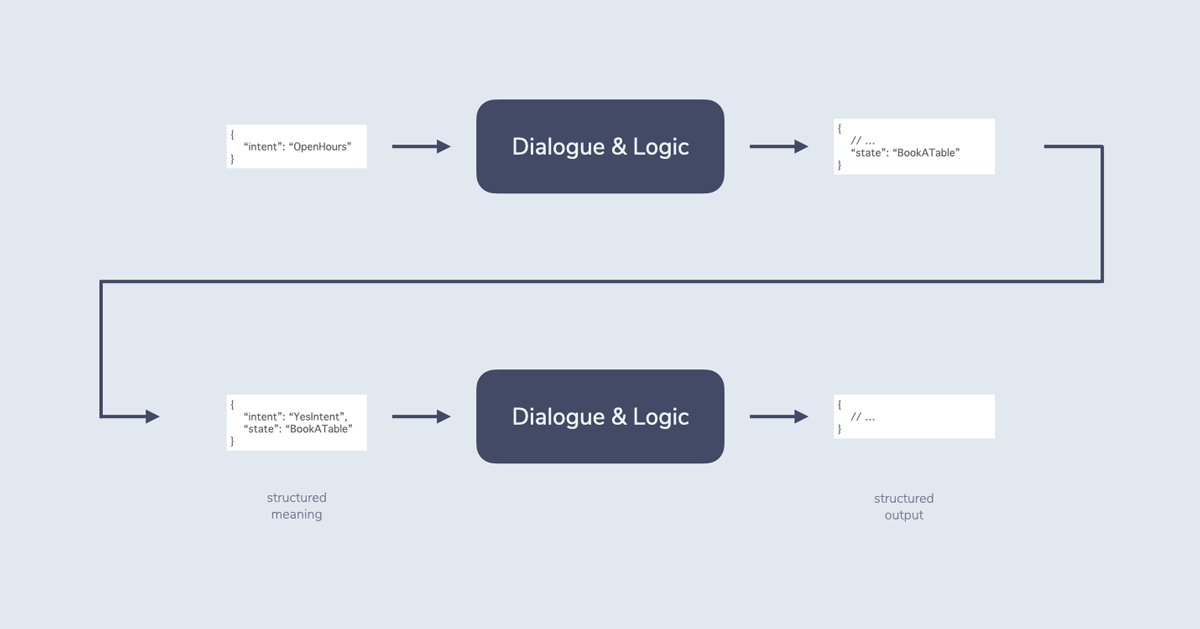
For context and state tracking, finite state machines often use a single value like a string of text. When you return a response that requires an additional turn, you save the current state, for example BookATable.
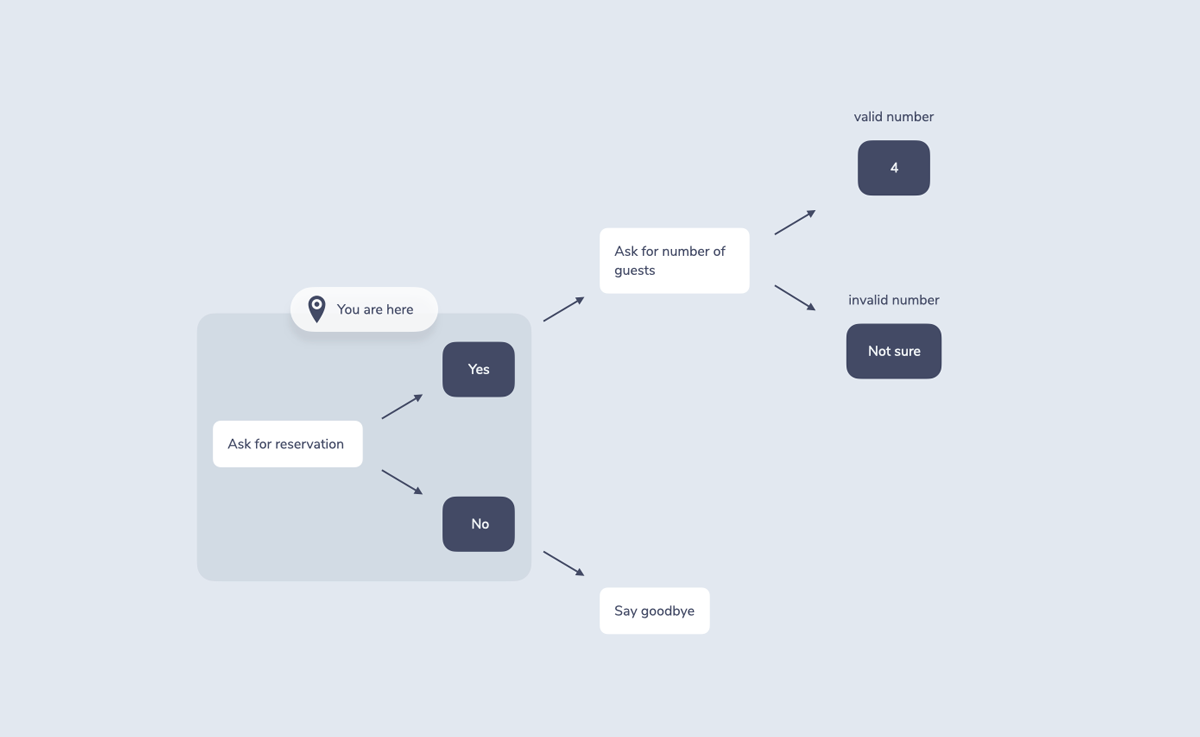
In a flowchart this could look like a “you are here” pin that helps it remember the last node of the conversation:
The control part of dialogue management then uses this state to determine next steps. This can be understood as following the flowchart to the next node.
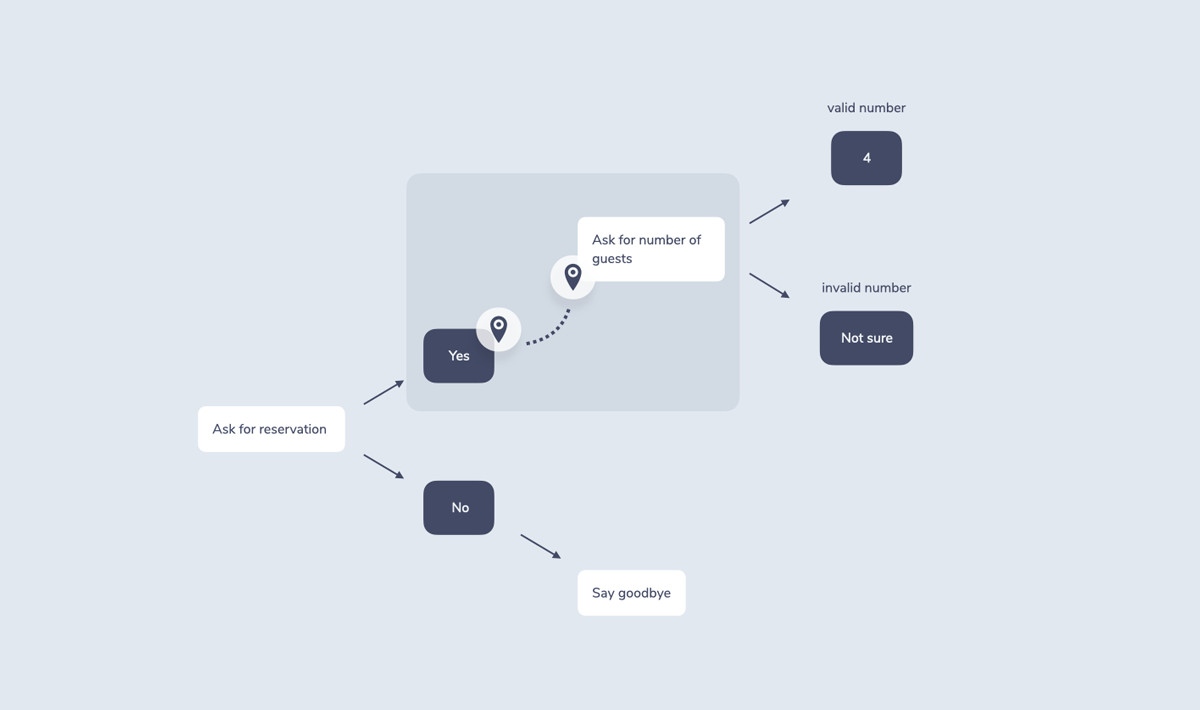
It then stores the new state for the next incoming request:
Many development tools like Jovo have state management built into their systems to allow for simple dialogue state tracking.

Finite state machines are a helpful holistic approach to structuring conversational systems. Flowcharts are a known concept and are relatively easy to read, understand, and communicate. This often makes state machines the tool of choice for cross-functional teams that work on conversational experiences.
The challenge of finite state machines can be their more or less rigid structure. Natural language is so open and flexible, trying to put a conversation into a 2 dimensional, tree-based process can feel mechanical and error-prone.
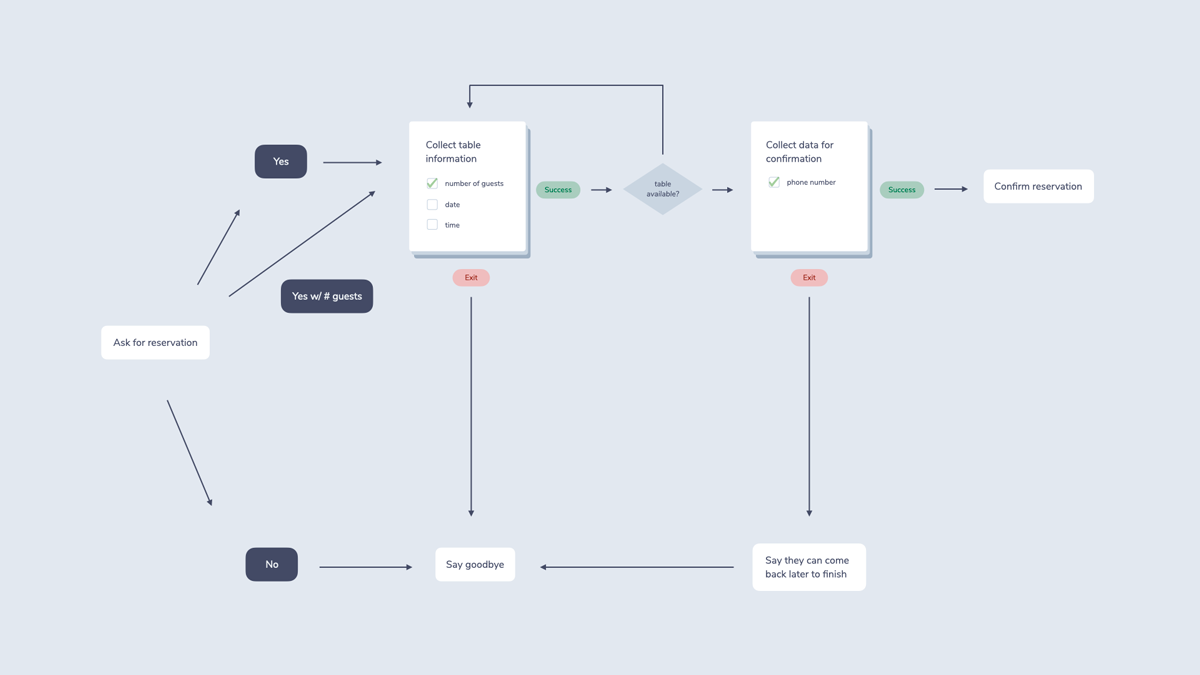
This is especially true for interactions that require a lot of user input. Let’s use our restaurant booking example again. We might need the following information before we confirm the reservation:
- Number of guests
- Date
- Time
- Phone number
Asking for each of the values step by step might feel more like filling out a form than having a conversation. In a natural dialogue, people would answer if they want to book a table in a variety of ways. Here are a few examples: “Yes”, “Yes, for 4 people”, “Yes, but a little later”, “No”, “How about the day after?”
A flowchart representing some of the potential interactions could look more like this:
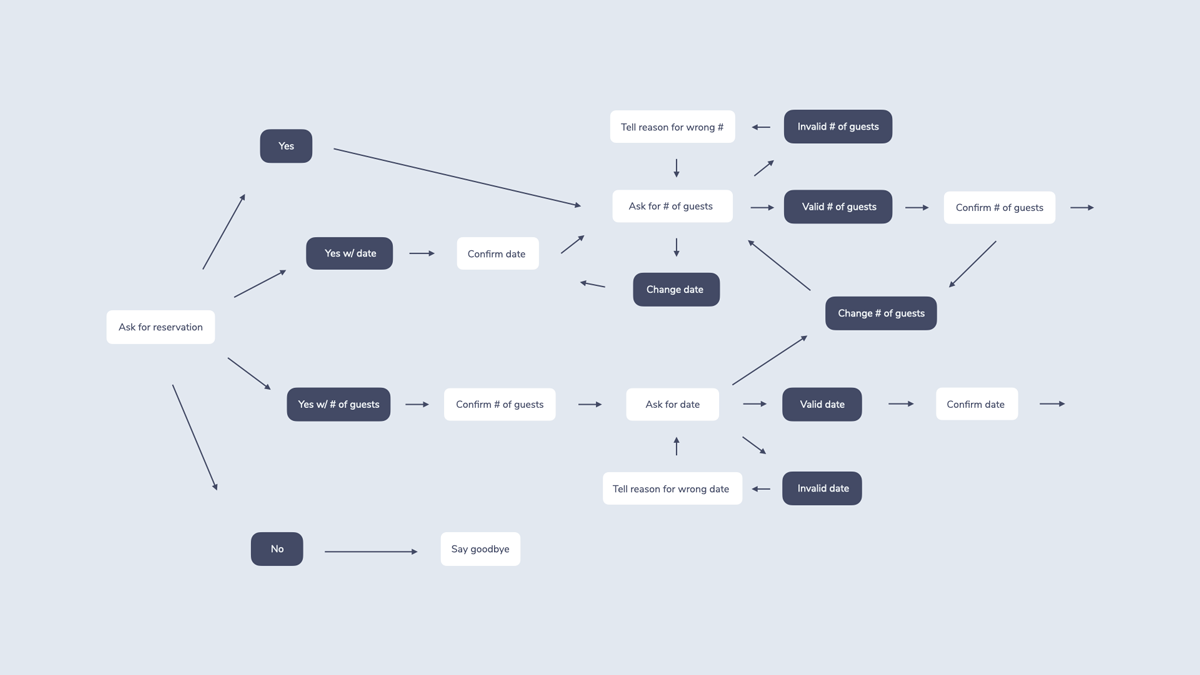
As you can see from this (still very simplified) chart, Implementing all possible interactions can be difficult, even impossible for some use cases. This is also referred to as the state explosion problem. Chas Sweeting illustrates this challenge in his great post The heavy-lifting required to build Alexa Skills & conversational interfaces.
And all the points mentioned above don’t even cover other types of context that were mentioned in previous sections of this article. Just to mention a few examples, where would we highlight differences depending on the time of day, the device, or specific user preferences?
Let’s take a look at other dialogue management techniques that attempt to solve those problems.
Form-Based Dialogue Management
Form-based (or frame-based) systems focus on the data needed to proceed, not on the conversational flow. This type of dialogue management is especially useful for slot filling, which is the process of collecting required user input.
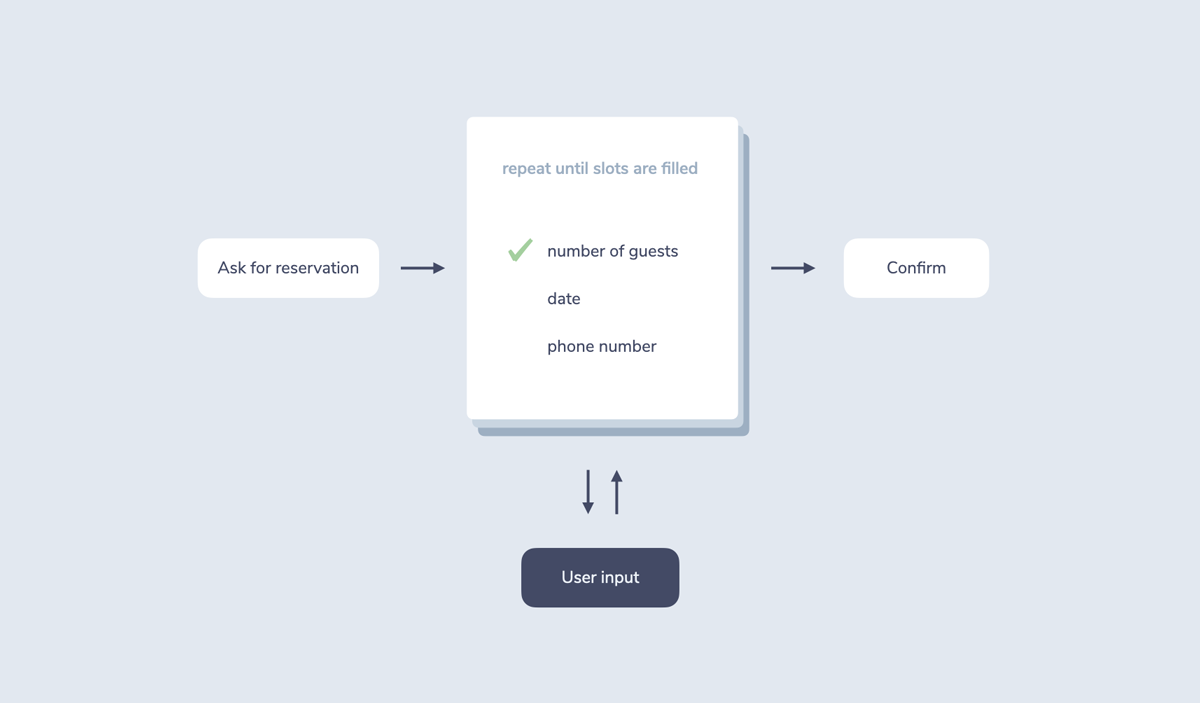
A form (also called frame) can be seen as a sheet of data that needs to be filled. The next step of the conversation is only reached when all required information is collected.
This frees up the design process of a conversational system by not having to design a new state machine branch for any potential interaction. Instead, it offers an abstraction by relying on clear rules, including:
- Source: The information we collect could either be implicit (already known from previous interactions or other data) or explicit (stated by the user).
- Prompt: How we ask for the information, for example "To send you a final confirmation, may I have your phone number?"
- Priority: Some slots could be required, some others optional.
- Sequence: Data could be collected one by one or even in a single phrase (“4 people at noon tomorrow please”).
- Quantity: There could be multiple values for one type of information, similar to Alexa’s multi-value slots.
- Validation: What type of data do we expect and how do we handle cases that the system can’t understand? How can we make sure a user isn’t stuck in a loop if their input isn’t accepted?
- Confirmation: Depending on the importance of some of the data, we could use implicit (“Alright, 4 guests. [...]”) or explicit (“I understood 4 guests, is that correct?”) confirmation to make sure we get everything right. Confirmation can happen for each individual slot, and also a final confirmation when all the necessary data is collected.
- Adjustment: The user should have the ability to make corrections (“Ah, wait, 5 people”).
Form-based systems track what data was already collected in an overview called task record. This record is retrieved as one element of dialogue context.
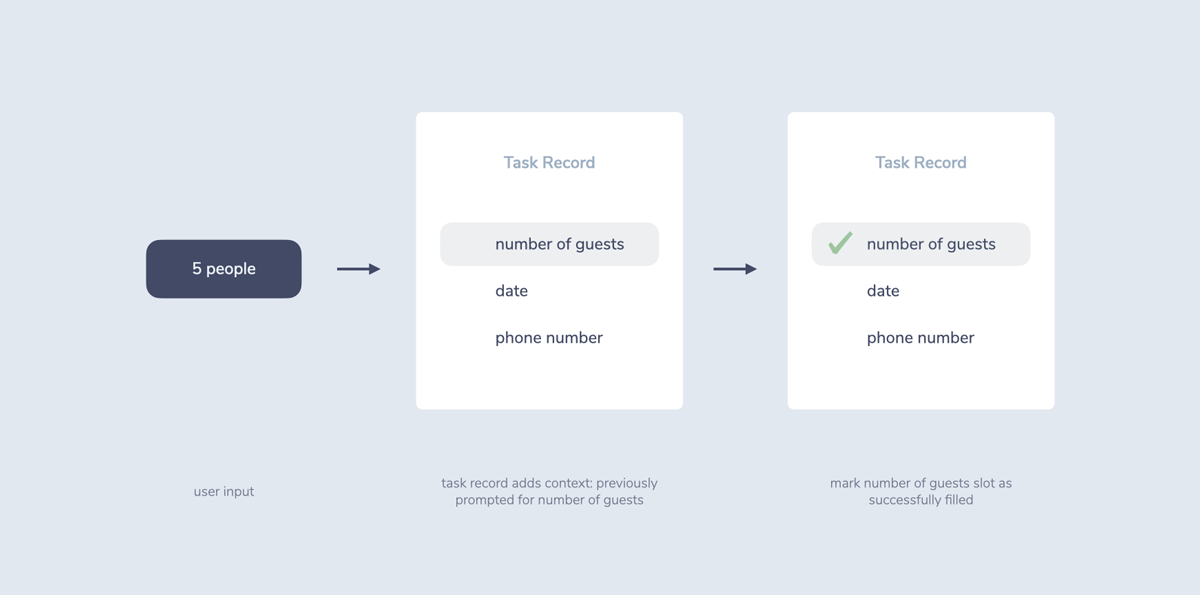
The control part of dialogue management then uses this record to prompt for elements that are missing.
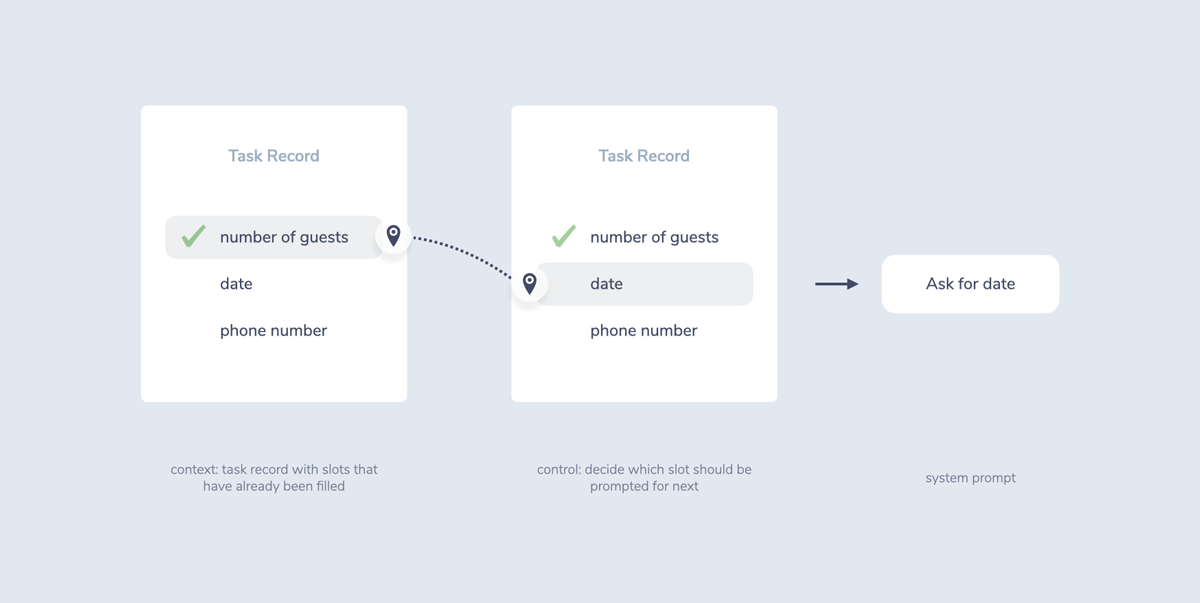
Advanced form-based systems also don’t necessarily have the user tell the values in a specific order as defined in the task record. The customers are able to decide which slots they want to fill when, and even tell information in one sentence like “3 people at noon, please.”
Concepts like the Alexa Dialog Interface, Dialogflow slot filling or Rasa Forms implement versions of form-based dialogue management.
While this approach solves some of the issues of finite state machines, it’s still a mostly rules-based approach: Each conversation needs to be explicitly defined. The design and build processes might take less time because some parts are abstracted by adding rules. It still requires manual work, though, making it difficult for the system to handle unanticipated interactions.
Let’s take a look at an approach that attempts to solve this by using machine learning.
Probabilistic Dialogue Management
Instead of relying on rules, probabilistic methods look at existing data to decide about next steps of the conversation.
There is an ongoing debate in the conversational AI industry whether rules-based dialogue management techniques like finite state machines will ever yield good enough results.
As mentioned in a previous section, natural language is so open that it’s difficult to create rules for each potential interaction between a system and its users. Probabilistic dialogue management promises a solution for this: By relying on data and machine learning models instead of rules, it offers more natural and scalable ways to automate conversations.
Some tools that already implement this are Rasa (using stories to train the model) and Alexa Conversations.
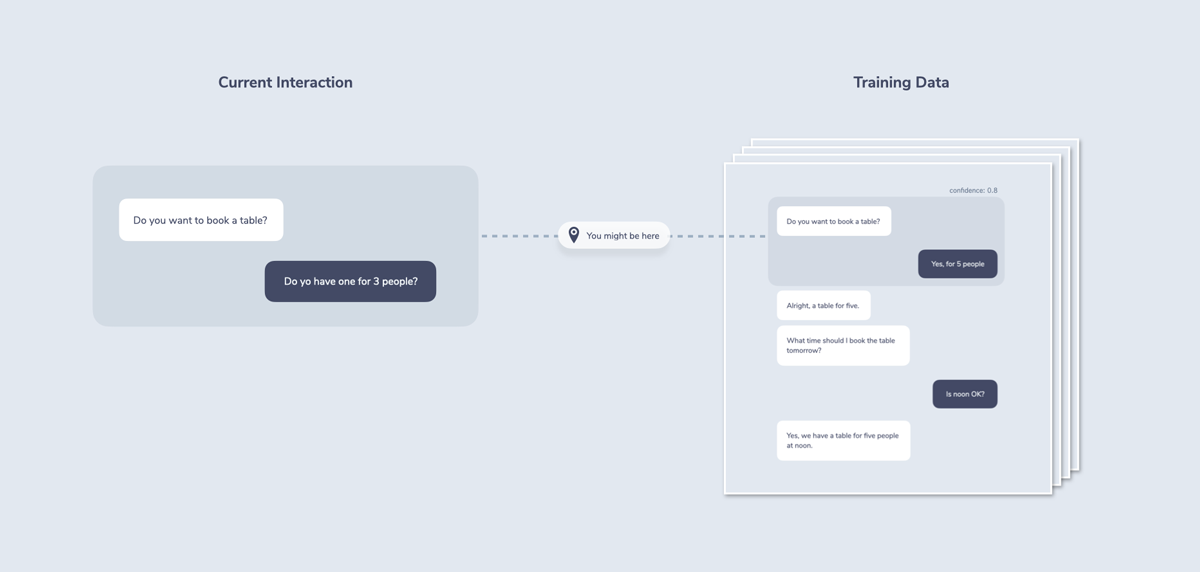
Probabilistic dialogue management works by using sample data in the form of conversations. Instead of looking at just one sentence (usually the case for natural language understanding), a complete conversation across multiple turns is considered.
This data is labeled by humans and then trained by a machine learning model. The advantage of this approach is that forces us to test our system very early in the process and learn from real world interactions. By looking at conversation data, we can see what our users wanted from the system. The disadvantage is the amount of training data that is potentially needed for robust interactions.
The system makes an educated guess about the dialogue context by looking at past interactions and how they might fit into the machine learning model. This is sometimes also called a state hypothesis or a belief state.
Some approaches also calculate multiple hypotheses and assign probabilities. This is especially helpful if the system encounters at a later point that its main hypothesis was wrong. It can then go back to another hypothesis and try again.
The control part of dialogue management then looks at these hypotheses and determines next steps using the model based on training data.
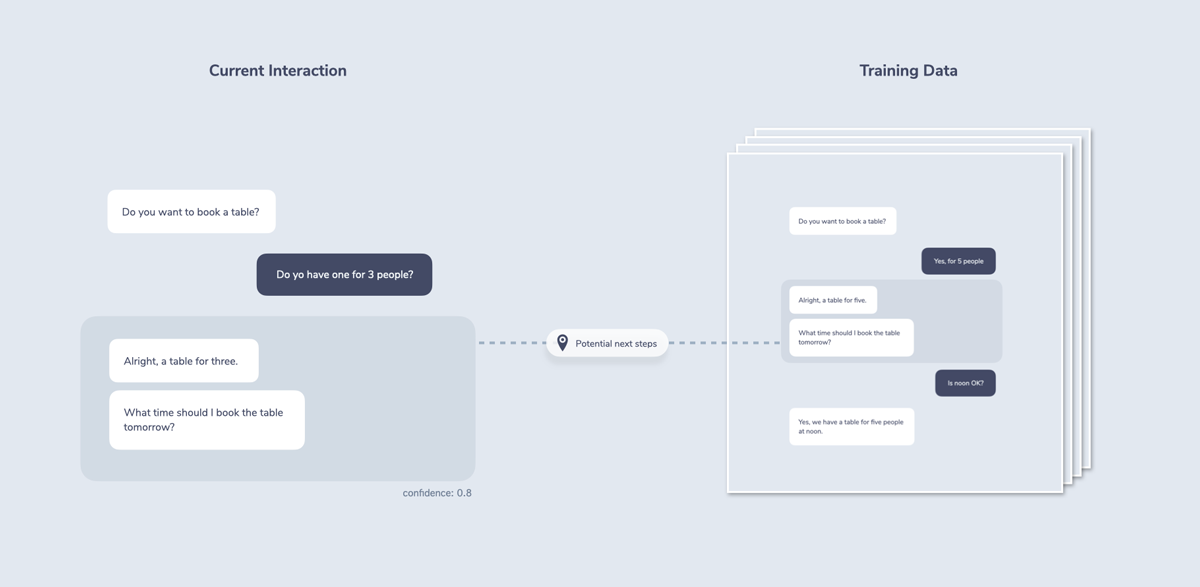
By looking at the training data, it can seem as if there’s no real difference between writing stories (training data) for probabilistic dialogue management and defining paths in a state machine. Aren’t both some kind of rules?
The big difference is the following: While rules-based systems need a clearly defined rule for each type of input, machine learning based dialogue management is trying to understand unanticipated input that was not clearly defined before. And the more training data is available, the better it is supposed to get at its job, promising a scalable approach to dialogue management.
While the probabilistic dialogue management approach comes with many advantages, there are also some things to consider.
First, it usually requires a lot of training data, which causes an initial investment for data labeling. This also means that bigger companies with more resources and usage are at an advantage.
Also, due to the machine learning approach, a lot of the decision making of the system is outsourced to a “black box” that can make it difficult to debug certain behavior in a deterministic way. The more training data and use cases are covered, the more difficult it might be to dive into problems and make changes.
Overall, probabilistic dialogue management is an important approach that I believe will be integrated into any conversational experience in the future. Tool builders around the world are also working on solving the issues mentioned above by combining different approaches. More on that in the next section.
What’s the Ideal Approach to Dialogue Management?
This post provided an overview of dialogue management with its two main tasks: context (where in the conversation are we right now?) and control (where should we go next?).
We took a closer look at these three popular approaches that manage conversations in different ways:
- Finite State: Using a state machine (or flowchart)
- Form-based: Using a task record of slots to fill
- Probabilistic: Using training data
We learned about the pros and cons of each of the methods. While rules-based dialogue management (finite state machines and form-based systems) offers full control over the user experience, it can be tricky to build it in a scalable way to respond to all sorts of unanticipated input. Probabilistic dialogue management offers more scalability with the potential drawbacks of needing large amounts of training data and giving up some control to machine learning models.
The question now is: What’s the ideal approach?
In my opinion, it doesn’t have to be black and white. For some interactions and use cases, a state machine with clear rules might make sense, for others a probabilistic method might be more effective. Powerful conversational systems mix them for the best outcome.
For example, by mixing the concepts of a finite state machine and form-based dialogue management, you can declutter the process of input collection while still having a clear, deterministic process for next steps.
Or, a probabilistic approach could delegate to a rules-based system for specific interactions.
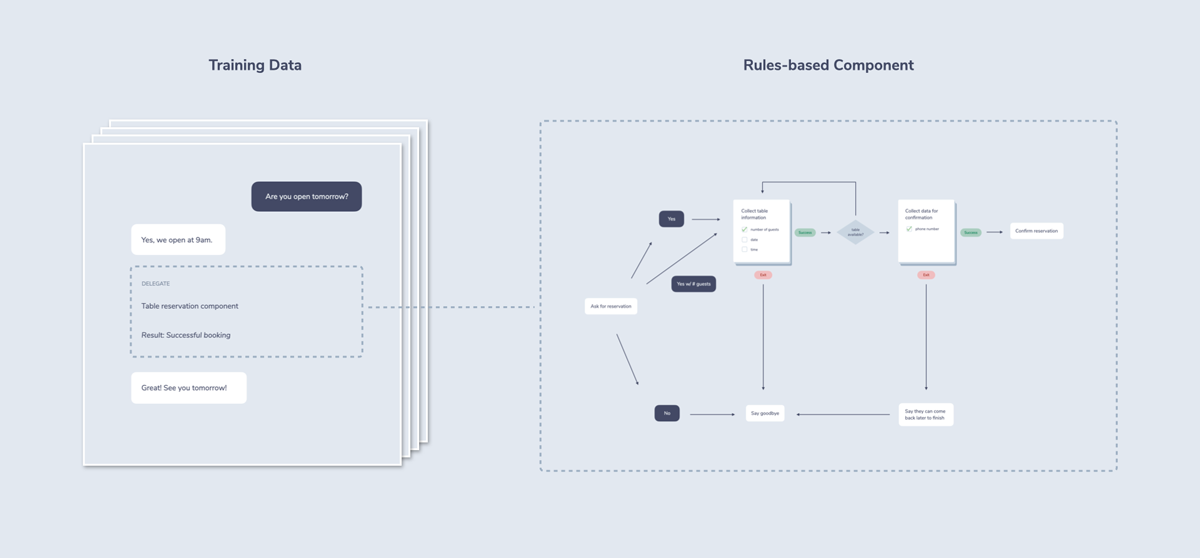
There are some tools that already support a mix of these dialogue management types:
- Rasa offers rules, forms, and probabilistic methods.
- Alexa offers the ability to build custom skill code (rules), a dialog interface for slot filling (forms) and the newly added Alexa Conversations (probabilistic) feature.
I suspect that we’re going to see more tool providers add different methods of dialogue management in the near future.
Zooming in and out
While doing research for this post and looking at the example illustrations of mixed methods from the previous session, one thing became clear to me: One of the most important features of designing and building conversational systems is the ability to zoom in and out.
In some cases, it’s important to dive into all the details. What should I do if a user wants to make changes to their previous input? How do I prompt for a slot value? In other cases, it’s important to keep track of the bigger picture. Combining different dialogue management methodologies can help with this from both a design and development perspective. And the full value of this can only be unlocked if elements of the system are modularized in the right way.
This is why, in my next post, I’m going to introduce a topic called “Atomic Design for Conversational Interfaces.”
Finally! I just published my longest article so far:
— Jan König (@einkoenig) May 26, 2021
✨ Dialogue Management: A Comprehensive Introduction ✨
- 3,000+ words
- almost 30 illustrationshttps://t.co/AxJlQSUm4Y pic.twitter.com/LcpW3oICc1
Thanks a lot to Julian Lehr, Mark Tucker, Andrew Francis, Giorgio Robino, Ben Basche, Manja Baudis, Brielle Nickoloff, Matt Buck, Alex Swetlow, and Lars Lipinski for reading drafts of this post.
I also tried a new experiment: While working on the post, I shared insights and open questions on Twitter. I learned a lot from the feedback and discussions there! You can find a collection of all tweets here.