Introducing Jovo v3, the Voice Layer
Doubling down on voice experiences that work anywhere


A little over a year ago, we released Jovo v2, a more powerful way to build voice applications that work across platforms like Alexa and Google Assistant.
Jovo has since become the go-to open source framework for voice app development, powering tens of millions of live interactions every month, with 20,000+ created projects and 70+ contributors to the open source code so far.
And today, we’re excited to take Jovo to the next level: Jovo v3 is the open source voice layer that allows you to integrate voice into any product or device.
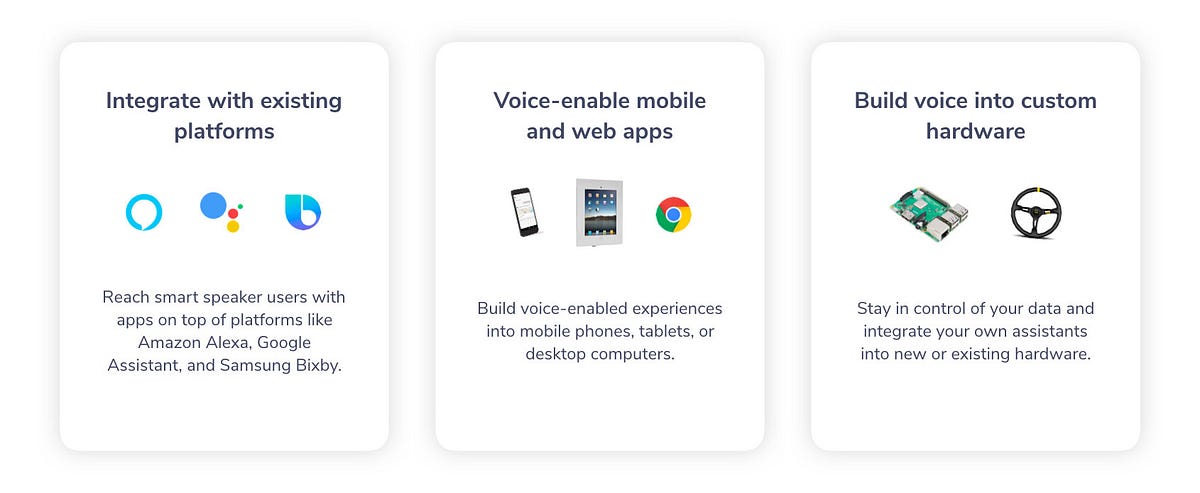
Here are some of the features that got added with v3 (read the technical announcement for more details):
- Jovo RIDR Pipeline: ASR, NLU, and TTS Integrations
- Build voice and chat experiences for the web, mobile, and custom hardware
- Build capsules for Samsung Bixby with Jovo
- Build phone assistants with Jovo and Twilio Autopilot
- New features that make voice app development easier and more powerful: Conversational Components and Input Validation
You can also watch the video here:
The Most Important Trend in Voice Today
When we started working on Jovo, voice was mostly seen as a platform. Companies built apps on top of the major voice assistants mostly for marketing reasons: they wanted to reach new potential customers through Alexa and Google Assistant.
The more we work in this space, the more we think that smart speakers can be seen as training wheels. Consumers are growing to expect to be able to use voice as a modality when interacting with technology. We sometimes call this the Smart Speaker Ripple Effect.
When voice becomes one of the most important elements of human-machine interactions, do companies really want to put all their fate in the hands of a few gatekeepers? We’re already seeing that companies are starting to build their own specialized assistants.
Businesses are starting to think in product ecosystems today, and we’re providing the layer to add voice to the mix.
Jovo v3: The Open Source Voice Layer
The biggest addition in Jovo v3 is our RIDR Pipeline that enables you to build voice experiences that work with any device or platform.
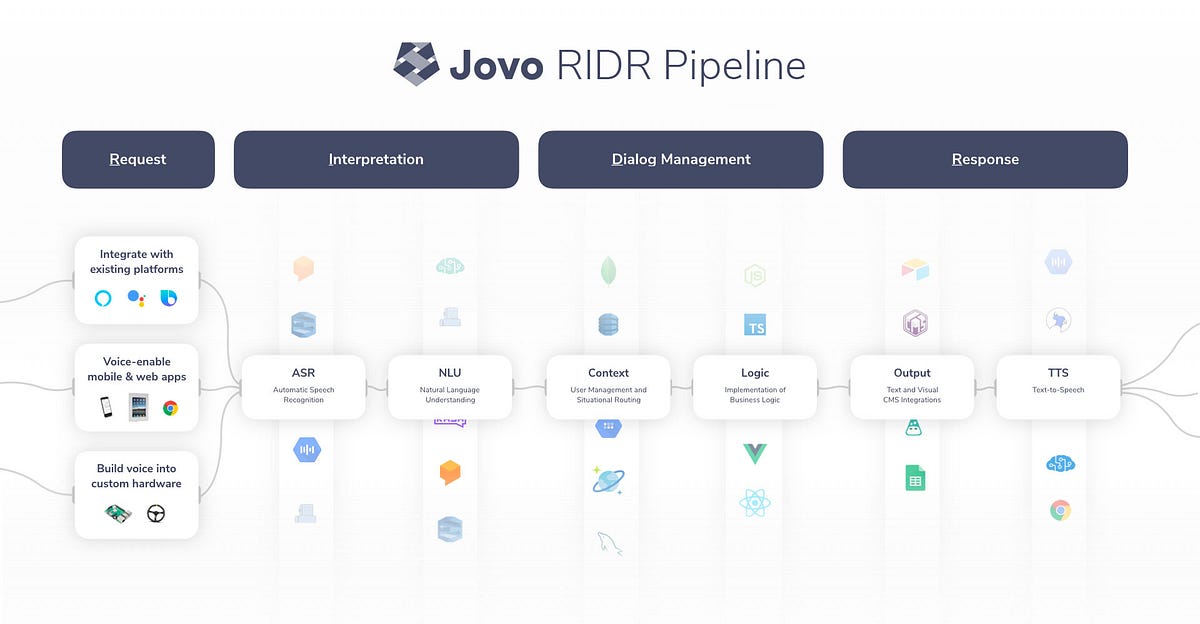
The Jovo Framework is free and open source and allows you to replace and customize any building block. In a time where voice becomes an essential part of product strategies, we want to help companies stay in control and embed our tools into their own infrastructure and scalable enterprise stack.
And this is just the beginning.
Jovo’s Mission: Enabling “Context-First” Experiences
The right information, at the right time, on the right device.
We’re especially excited for our web and mobile integrations because they open up a lot of possibilities for multimodal experiences.
Almost 3 years ago, I published this article about building multimodal user experiences:
https://context-first.com/alexa-please-send-this-to-my-screen-6f4839eb415a
A lot has changed in the last 3 years, our vision remained the same: We want to enable product teams to build product systems that deliver the right information, at the right time, on the right device.
Jovo v3 is the next step towards connected multimodal user experiences.
We can’t wait to continue that journey with you.
Next Steps
- Get started: Follow our Quickstart Guide.
- Support Jovo: Give us a star on GitHub
- Need help? Contact us for an enterprise support package