Introducing Context-First
Exploring voice and multimodal user interfaces in a new publication

We live in a connected world.
We spend our days with various devices: Computers at work, phones and wearables on the go, smart speakers at home—our interactions with technology are spread across different touchpoints and interfaces.
The possibilities are endless. Yet, how we use technology often feels disconnected, even clunky.
Is this going to change? If yes, how and when?
Towards a Multimodal, Multi-Device Future
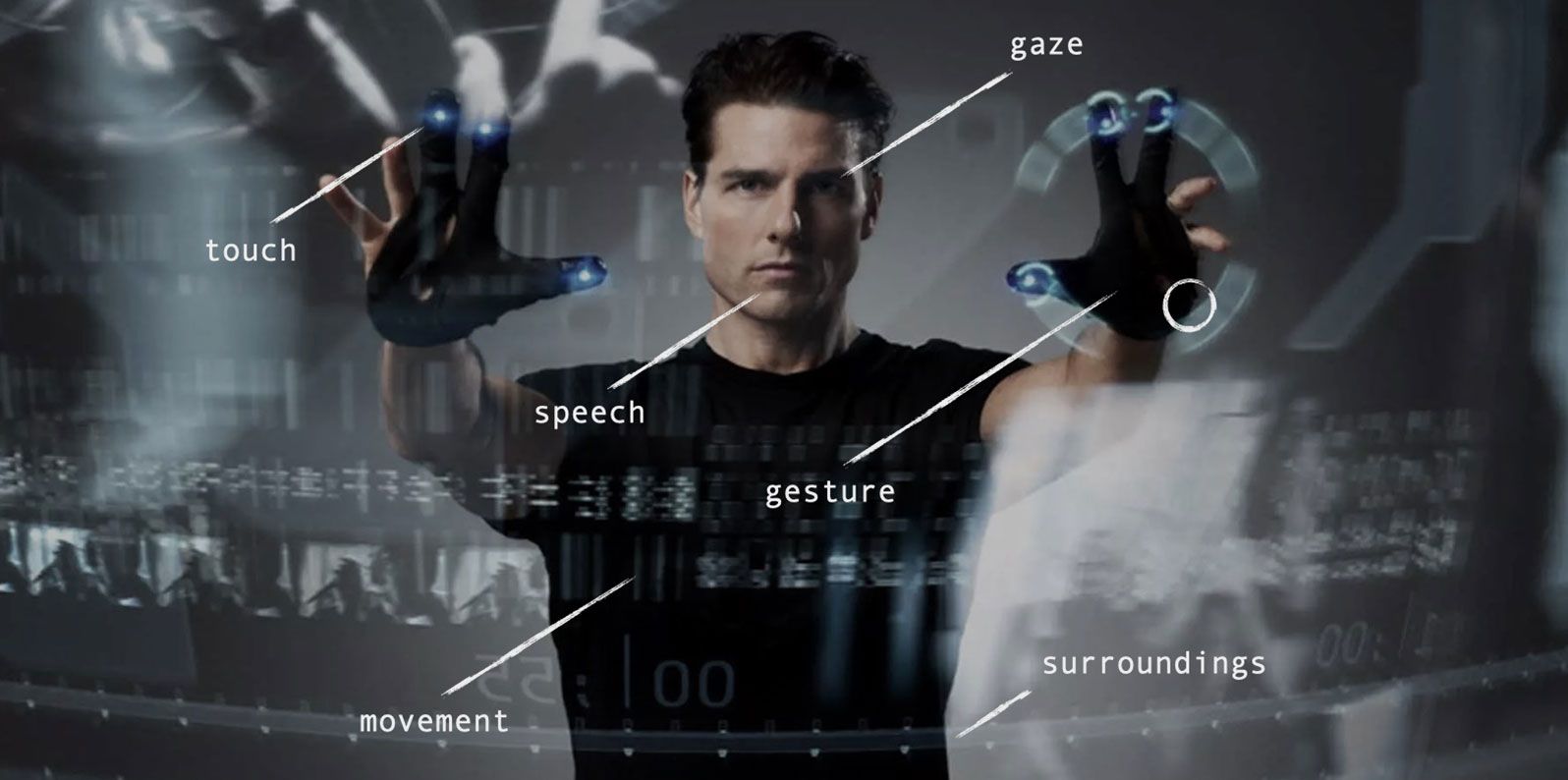
At least since Put That There, many have seen multimodal user interfaces as the holy grail in human-computer interaction. Being able to use any modality (speech, touch, gestures, eye gaze) that best fits your current situation is seen as liberating and inclusive for a wide range of users.
Of course, this has been greatly influenced by SciFi, too. When people envision future multimodal user experiences, examples like Minority Report often come to mind where people are standing in front of gigantic machines that support all kinds of input modalities at once. Is this practical today?
3.5 years ago (shortly before Jovo joined betaworks Voicecamp), I published an article called Alexa, Please Send This To My Screen with some early thoughts on voice experience design. I came to the conclusion that most voice experiences need to be embedded into wider product ecosystems to become truly useful. To me, one of the biggest differences between SciFi and technology today is that our interactions are now spread across different devices. There is no more “one machine does everything.”
The new multimodal experience is not just one device that supports everything, it’s a product ecosystem that works across devices and contexts.

And it seems like things are progressing. When I published the article, smart speakers were mostly disconnected voice-only devices. Just a few months later, the Echo Show was introduced as the first Alexa smart display and Google Assistant became more deeply integrated into Android phones, allowing for some early continuous experiences like “send this to my phone.” I’m confident that it soon will be normal for any device to be shipped with a microphone.

With all these new devices added to the product mix, it gets more and more complex to design, build, and improve connected experiences. Which devices and modalities should you build for? It’s easy to lose track of the user's needs with all these technological possibilities.
Context-First, a Term and Publication
“The right information, at the right time, on the right device.”
The quote from above was adapted from Michal Levin’s great book Designing Multi-Device Experiences that I read a few years ago. For us, this is what contextual experiences should be all about: delivering value on the best available device and modality.
At Jovo, we've been mentioning the term Context-First for a while, most prominently in our v3 launch announcement. There is so much overlap between “voice” and “multimodal” experiences that it always felt weird to us to use terms like “voice-first.” With more devices being available, context plays an even more important role in product design decisions. It was important for us to find a term that reflects this.
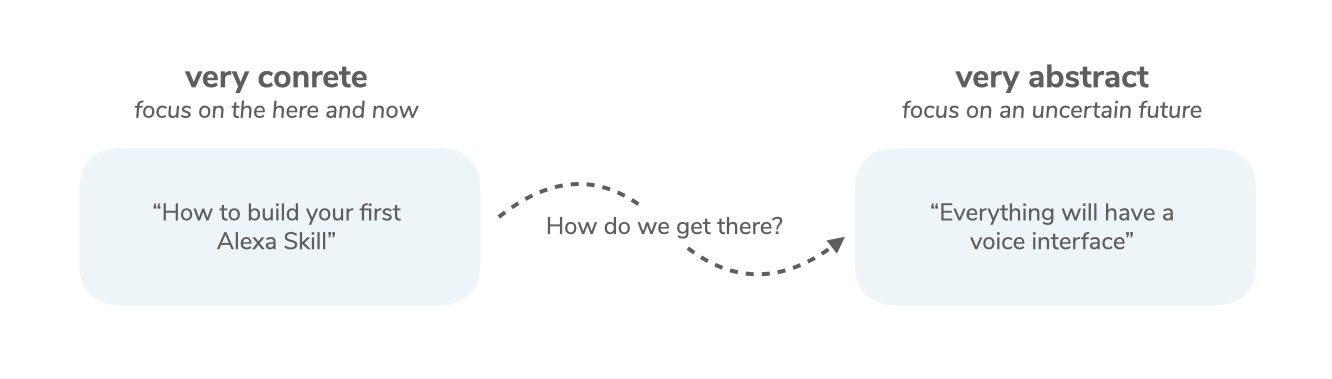
We want to use this publication for documentation and open learning about building context-first products. When I started working on my masters’ thesis, there was not a lot of actionable information available on multimodal user interfaces. It was either too concrete (focused on the “here”, e.g. simplistic tutorials) or too abstract (focused on the “there”, e.g. very visionary, futuristic essays). The industry still lacks content that focuses on the in-between (here are some counter examples).
Here are some topics that we will likely cover:
- Challenges that need to be solved to get from “here” to “there”
- Deep dives into different device types and modalities
- Case studies and examples that focus on a specific vertical
- Providing business context for the more technical Jovo announcements
What are you interested in? Say hi on Twitter and let me know! @einkoenig
I just published a new blog post:
— Jan König (@einkoenig) August 31, 2020
✨ Introducing Context-First ✨https://t.co/6pJhjTkDaF 1/x pic.twitter.com/JX5NfmoIaO